
Hagyó Miklós felelősen jár el
2009.08.31. 17:36
Bréking, Hagyó "felelős szocialista városvezető" Miklós példaértékű lépésre szánta el magát. Miután magas nívójú szakmai felügyelete alatt a BKV-t minden valószínűség szerint szétlopták, a budapestiek közlekedésének veszélyeztetettsége miatt lemondott a BKV felügyeletéről.
Hagyó Demszkynek írt búcsúlevelében kifejezi reményét, mely szerint a valódi felelősök is hasonló lépéseket tesznek a főváros közösségi közlekedésének biztonságos működtetése érdekében.
Hagyó Miklós informátoraink szerint miután ezen példaértékű, valóban felelős lépését megtette, elbattyogott a legközelebbí buszremízbe, a meglepett portástól felvette az egyik busz kulcsait, majd elhajtott.
Hagyót több járókelő is látta Csepelen, amint a lopott 159-es busszal 120-szal száguldott, majd egy fának ütközve totálkárosra törte a járművet.
A kiérkező rendőrök arra irányuló kérdésére, hogy mégis mit akart kezdeni a busszal, Hagyó azt felelte, hogy nem bírta a nyomást, amely az ellopott milliárdok társadalmi felelőssége miatt rajta nehezedett, így tegnap éjszaka elhatározta, hogy a BKV után az életéről is lemond.
Sajnos a BKV után ezt is elkúrta...

Command Completion Coalescing
2009.08.30. 19:56
A nagyon terhelt szerverek (egyik) ősellensége mindig is a gépre aggatott mindenféle periféria volt. Nem elég, hogy lassúak, sosem hagyják dolgozni a kernelt, mindig akarnak valamit, megszakításokat (interrupt) generálnak.
Az egyik ilyen kritikus pont a hálózati vezérlő (pld. ethernet NIC), amely a sok apró kerett miatt tonnaszám próbálja a kernel figyelmét magára vonni és a kereteket a pufferéből továbbadni, ha nagy a forgalom. Így hiába gyors amúgy a gép, hiába tud nagy keretekkel bámulatos teljesítményt elérni, kisebb csomagokkal jelentősen visszaesik a teljesítmény.
Ezért is a PPS (Packet Per Sec) a legfontosabb egy routernél, vagy tűzfalnál, nem pedig a nyers átviteli sebesség (amivel könnyű trükközni, hiszen maximális keret/csomagméreteknél könnyen összejön a wirespeed).
A problémára az első (általam ismert) megoldás a FreeBSD ethernet pollingja volt (Luigi Rizzo által), amely lényegében lekapcsolta a NIC interrupt küldését, és néha ránézett, hogy van-e új keret, ha pedig volt, elhozta azokat.
Ez nyilvánvalóan rengeteget segített olyan esetekben, amikor már annyi interrupt volt, hogy a kernel szóhoz sem jutott (ismerős állapot volt régebben az egy processzoros, nagy hálózati forgalmat kapó gépeknél), viszont a megoldás hátránya is szembetűnő: mivel a keretek akkor kerülnek feldolgozásra, amikor egy nagyobb adagot elhozott belőlük a kernel, nem pedig akkor, amikor beérkeznek (IRQ), a feldolgozás ideje nő (késleltetés).
Később hasonló funkció került a gyorsabb (jellemzően gigabites) NIC-ekre, interrupt coalescing néven, amely ugyanezt csinálja, de a NIC firmware-ében, azaz nem keretenként próbálja célba juttatni a csomagot, hanem bizonyos feltételek szerint várva (feltorlódott csomagszám, és időzítés) többet, egy csomagban.
Korábban volt szó róla, hogy az ethernet NIC-ekhez hasonlóan a CAM-ban (a FreeBSD SCSI alrendszere) is implementálásra kerül hasonló funkció, amely a diszk IO nyomása alatt küzködő rendszereken segíthetett volna, de (úgy tudom) ebből semmi sem lett.
Jó kérdés persze, hogy mekkora létjogosultsága lett volna ennek, hiszen jó ideig úgy tűnt, hogy a diszkek egyeduralma egyhamar nem fog megdőlni, és a tárolórendszerekben az egy kontroller, egy (kevés) virtuális diszk, mögötte sok valódi diszk (RAID) elv valósul meg, legalábbis a szerverekben. Ezeknél pedig azért ritka a sok tíz-, százezer, vagy esetleg milliós nagyságrendű mozgolódás, hiszen a diszkek tranzakcionális sebessége a terhelt állapotban tipikus random IO-nál ennél jóval kevesebb.
Változott azonban némileg a helyzet, hiszen az SSD-k megjelenésével sokkal pörgősebb tranzakciók várhatók, amelyek ráadásul egyre nagyob párhuzamossággal történhetnek.
Az AHCI 1.1-es verziójában (nem ma volt) meg is jelent a fenti technológia, amit az Intel Command Completion Coalescingnek hív. A működése ugyanaz, mint az Ethernet világban: a bekapcsolt portokon egy timer számol, ha van forgalom, és ha nullára ér, megszakítást kezdeményez.
Ezt implementálta most Alexander Motin a FreeBSD-ben, aki Søren Schmidt helyett pátyolgatja mostanában a FreeBSD (S)ATA részét.
A legfontosabb paraméter, a timer a hint.ahci.X.ccc sysctl-lel szabályozható.
Érdekes lenne megnézni pár gyors SSD-vel, hogy milyen hatása van...




Képrejtvény
2009.08.13. 20:12
Eltévedtem kicsit a szovicc.blog.hu-ra, ami mostanában inkább egy képrejtvény-site.
Ma reggel eszembe jutott nekem is egy ilyen, lásd:

A megfejtés:
Tanítsd nagyanyádat!
2009.08.12. 22:01

Klikkelj nagyi!
Nem, az egér, nem a spejzban van, hanem az asztalon. Jaj, mássz már le a székről, nem él. Tologasd. Vidd a jobb felső sarokba.
Neem, ne az egeret, a mutatót!
Na most keressünk valamit. Igen, ez a gúgel. Mit keresnél? Szabásmintát? Nem tudod? Jó.
Akkor menjünk a fészbúkra. Nem bírod kimondani? Jó, akkor az iwiwre. Na, így. Keress ismerősöket....
... ja, néha előfordul, hogy a Szabó Klárára egy meztelen nő jön be, amint éppen a kutyájával... Huh, nagyi, hogy a frászba találtad ezt?
Na nézzünk mást. Próbálj csetelni, addig én telefonálok egyet....
... mi? Mit akarnak? Pénzért szexelni? Veled? Meg hogy nagyapát is vidd? Atya ég nagyi, hol a fenében találtad ezeket? Tessék? Hogy mi az a LOL, meg ROTFLMAOPIMP? Huh.
Na jó, nagyi, figyelj, nekem erre nincs időm, neked profi kell...
Parsing made fun
2009.08.10. 17:12
Na ez az, ami eddig sosem jutott eszembe. Mármint az, hogy a parsing (adatstruktúrák felbontása, elemzése) vidám dolog is lehet.
Legutóbb például -amikor pythonban írtam OpenBSM parsert- határozottan éreztem, hogy kell legyen valami jobb mód is erre, de egy-két gyengére sikerült keresés után elraktároztam magamban, hogy ha van is, mélyebbre kell ásnom.
Azóta nem kellett újabb formátumot megértenem, és feldolgoznom, így nem is kerestem ilyen eszközt, de ma szembe jött velem a megoldás a levelezőmben a "py-construct" nevű FreeBSD csomag személyében.
A cucc weblapjának nézegetése közben a szerző "miért kellett még egy n. parsert írnod B+?" FAQ-ra adott válaszát teljesen át tudtam érezni:
Before I wrote Construct, I did a little research on the subject, and looked at things like ethereal, the protocol analyzer. I thought ethereal must have some uniform way of defining it's dissectors, since they parse anything from ARP to X11.
But to my great disappointment, I found a directory of more than 850 hand-written ad-hoc C files, some more than 200KB in size, some looking like ASCII-art code. Moreover, ethereal doesn't use an object to hold the parsed information -- it simply adds it directly to the GUI textually using format strings. Ugh.
When I realized most other parsers/unpackers work that way, I set off to write yet another parser.
Valami hasonlót éreztem én is múltkor.
A modul Wikipedia-lapján könnyen érhető példa van a TCP/IP/Ethernet parse-olására, a forrásban pedig előre készen van pár sűrűbben használt protokoll (DNS, UDP, IP pld), meg formátum (PNG, ELF32 stb).
Igen nagy kár, hogy a news szekció nem mutat túl nagy aktivitást:
News
- 2007.11.03 - added BML, a simple Binary Markup Language (like binary XML)
- 2007.04.09 - The PNG file format has been added to the SVN
- 2007.02.10 - Generating ASTs with Construct -- see the Sheep project
- 2007.01.20 - The Construct Community Effort wiki has been created
- 2007.01.19 - The Construct's coding-style guidelines
- 2007.01.12 - 2.00 is out. See the release notes
Ha időm engedi, megnézem, sokszor kellett volna már egy DNS/LDAP/DHCP/stb parser, aminek beadva a lementett, vagy real-time érkező csomagokat megnézhetem pld. egy szerver válaszidejét, vagy a válaszadás sikerességét.
Aki ismer, használ hasonlót (akármilyen más nyelven), ne legyen rest beírni a kommentekhez!

Dragonfly BSD
2009.08.07. 21:12
Hunger bíztatására gondoltam nekiállok kipróbálni a Dragonfly BSD-t is, hiszen a legújabb, 2.2-es kiadásban már production ready-nek van jelölve a HAMMER fájlrendszer.
Mivel a rendszer a FreeBSD 4-es forkja, kimaradt a masszív párhuzamosításból (pont ez volt a válás egyik oka), és az ötössel beindult nagy változások, és a kis számú fejlesztő miatt más dolgokból is (amd64 -bár ez lassan készül-, driver frissítések stb).
Emiatt túl sokat nem várok tőle, bár az egy szálú sysbench teszteken valószínűleg még előny is lehet abból, ha a kernelben nincs annyi mutex, mint a solari^Wkutyában a bolha, de ezt majd meglátjuk.
Azért majd, mert a tesztek sokáig futnak, illetve most nem is futnak, mivel pár bájt diszkre írása után a kernel read onlyba kapcsolta a fájlrendszert, és ezt logolta le:
(da1:ciss1:0:1:0): SYNCHRONIZE CACHE(10). CDB: 35 0 0 0 0 0 0 0 0 0 (da1:ciss1:0:1:0): CAM Status: SCSI Status Error (da1:ciss1:0:1:0): SCSI Status: Check Condition (da1:ciss1:0:1:0): ILLEGAL REQUEST asc:20,0 (da1:ciss1:0:1:0): Invalid command operation code (da1:ciss1:0:1:0): Unretryable error HAMMER(test): Critical error inode=-1 while flushing meta-data HAMMER(test): Forcing read-only mode HAMMER(test): Critical error inode=-1 while flushing meta-data HAMMER(test): Critical write error during flush, refusing to sync UNDO FIFO
Az UFS egyébként jól működik (nyilvánvalóan nem akar cache-t szinkronizálni), de a ciss driverben azért célszerű lenne ezt az esetet lekezelni...
Megírtam a szitakötős arcoknak, remélem javítják, mert nekem most nincs kedvem Dragonfly BSD-t fordítani...
Pina-projekt
2009.08.06. 16:35
Az újságírók mindig is szenzációhajhászok voltak, amely mostanában főleg a cikk címében csúcsosodik ki, hiszen a modern embert érő végeláthatatlan információtengerben az az egy sor a legfontosabb, amely eldönti, hogy elolvassa(kattint)-e a cikket az olvasó, vagy sem.
Az indexen szocializálódottaknak biztosan nem is túlzottan érdekes, nyomtatott sajtóban viszont -legalábbis a saját tapasztalataim alapján- eddig nem volt túl gyakori az ilyen:

Alig várom már (nem), hogy a gyerekem boldog mosollyal az arcán közölje otthon, hogy az oviban Lakatos Pinával aludt együtt a délutáni pihiszünetben. :-O
HUPwnie awards
2009.08.02. 10:22
Trey és Hunger vitája a Pwnie-díj győzteseiről odáig fajult, hogy akár megalakulhatna a HUP saját pwnie-díja is, amelybe aztán végre igazságosan lehetne jelölni az infolámerkedések csúcsait. Trey szerint már csak egy jó név kéne, amelyre szerintem adja magát a HUPwnie.
Össze is raktam gyorsan egy logót, vigyázat, pun intended!
És persze igazságtalan lenne, ha nem emlékeznénk meg az idei verseny győzteséről...


Massa hétfőn hazarepül Brazíliába...
2009.07.31. 16:43
... adja hírül a SportGéza.
A Brazil Nagydíj orvosa magyar kollégáit és a Honvéd-kórházat is dicsérte: ”Nagyon jó orvosok vannak itt, nagyon magas szinten dolgoznak, a kórház jól felszerelt, kitűnő az ellátás, minden szempontból remek”.
Bár biztosan kiemelt figyelmet fordítottak rá, ettől függetlenül gratulálok a magyar orvosoknak, és minden ott dolgozónak, remélem ez inkább a hazai egészségügy javát, és nem a további romlását (megelégedett hátradőlés, amire egyébként semmi ok) szolgálja.
Egyúttal őszintén remélem, hogy a hazaúton már semmi komplikáció nem lesz, mondjuk egy rugó formájában:

iphone, a telefonzorhaxxorok kedvelt cucca
2009.07.30. 21:45

Azt mondja a HUP, hogy az Apple szerint az iphone-nal tönkre lehet tenni a GSM tornyokat. Azaz a iphone a terroristák szuperfegyvere, hiszen olcsó (HAHAHA), és segítségével meg lehet bénítani a mezei urbánparasztok sugárkezelésében döntő szerepet játszó kreációkat, a "GSM tornyokat".
Persze ha ezt így kimondanák, lenne nagy pánik, meg fellendülés az appstore-ban, hiszen mindenki hozzá szeretne jutni a csodaszoftverhez, amellyel majd megmutatja a partikon, hogy ki az isten, hiszen mekkora királyság már egy gomb megnyomásával kiiktatni mindenki telefonját a közelben. Tisztára mint a mátrikszban, amikor Neóék EMP-ztek, vagy őket EMP-zték a polipok, vagy mi, csak ez zsírabb, mert nem a nyúl üregében van, hanem a Jósika utca 12/B II/1-ben.
Hátránya persze, hogy az Apple szerint jailbreakelni kell ehhez a telefont, hogy hozzá lehessen férni a baseband processzorához. De onnan már gyerekjáték (mint a jailbreakelés), és meg is nyílik előttünk az út a telkókhoz, akiket ezután kedvünkre szopathatunk.
Elárulom a titkot: nem kell hozzá iphone sem, bár azzal kétségtelenül l33t-ebb.
Bevallom megfogott ez a lehetőség, így gyorsan el is képzeltem a magam szegényes fantáziájával az első -nagy sikerű- appstore alkalmazás, a "Destroy your GSM tower v1.2" honosított változatát akció közben.
Fentebb látható.
Btrfs az exterminátor?
2009.07.29. 14:33
Folytatva a töménytelen mennyiségű sysbench kimenet feldolgozását, eljutottam a linuxos részhez. Itt négy fájlrendszer (ext2, ext3, ext4 és btrfs) szerepel, a futási feltételek megegyeznek az eddig leírtakkal.
A btrfs a következő generációs fájlrendszer, ezt még talán az ext4 fejlesztője is deklarálta. Nézzük meg, hogy teljesít a többiekhez képest!
A kernel 2.6.30-as volt, és bár ebben elvileg sokat javítottak a btrfs SSD-s teljesítményén, nekem sajnos ez (és persze sok más) kimaradt. Minden fájlrendszer a default mkfs paraméterekkel lett megformázva.












Szekvenciális olvasásban a btrfs magasan veri az ellenfeleket, HDD-vel és SSD-vel is. Érdekes (nem jártam utána) az ext3 gyengélkedése az SSD-vel, pedig hát itt nem kell írni, csak olvasni, abban meg jók szoktak lenni ezek az eszközök.
A random olvasásnál már annyira nem egyértelmű a nyerő helyzet, ott az ext4 próbálta leginkább felfesteni a diszk határait. Ugyanez látszik az SSD-nél is, az ext4 sokkal jobb teljesítményt ad le, mint a btrfs, az ext3 pedig továbbra is alig bír kivakarni valamit a flashekből.
Az írás teljes tükörképe az előzőeknek. A btrfs a HDD-n 8 kiB-os blokkméretig kemény 1,46 IOPS-t tudott produkálni, majd szétrohasztotta maga alatt a kernelt. SSD-n igen kiegyensúlyozott teljesítményt mutatott, és a merevlemezhez képest masszív teljesítményjavulás is látszik, hiszen az 1,46 IOPS helyett itt már 2,81-et kapunk, és azt megkapjuk minden blokkméretnél.
Vele szemben az extek sokkal jobban teljesítenek.
A random RW tesztnél a HDD szekcióból a btrfs hiányzik, mivel rögtön a teszt indulásakor szarrá fagyasztotta a gépet, de az SSD-vel is csak 64 kiB-ig jutott, ahol szintén eljátszotta ugyanezt.
Úgy látszik a random teljesítmény mellett még a megbízhatóságon is kell csiszolniuk a fejlesztőknek, de hát ez nem ritka egy ilyen fiatal fájlrendszernél.
Szokás szerint az IOPS grafikonok után jöjjenek a MiBps-esek:












26 nap, és Massa megint pályára lép
2009.07.27. 22:15
Az egész net tele van masszával...

Évek óta mondják, hogy a repülés mennyivel biztonságosabb -persze tudjuk, hogy ez is csak egy antimagyar világszintű érdekcsoport hatalmi manipulációja-, erre idén beindult valami, sorra potyogtak a gépek, amelyre a kétkedők végre elégedetten morzsolhatták a kezeiket (hacsak nem éppen egy repülőtéren vártak).
Erre mi történik, amikor minden normális polgár kint játszik a kertben a kutyával/gyerekkel/vízilóval, és a szünetben a hideg sörét kortyolgatja? Ez a brazil srác, ahelyett, hogy a honleányokkal szambázna, egy isten háta mögötti román városban lefejel egy kilós acélrugót. Olyat, mint amivel a kolbászt esszük, de ez fémből van, a formája is más, és biztos nem 220 belőle 10^3 g, így egészen biztosan gyorsan eltakarította a helyi ácélkómmandó a bizonyítékot.
Püff a javuló statisztikának, kiderült, hogy négy keréken közlekedni igenis kurva veszélyes! Főleg pirosban (pedig az még odébb van, hogy ebben az országban a pirosak vasat kapjanak az arcukba)! Mert hát ki a göcsörtös franc hallott már olyat, hogy egy repülő kilós rugónak ütközik, és lezuhan? Vadkacsának igen, nade rugónak?
Na de szerencsére itt van nekünk a felipemassaDOTcom, mint hiteles információforrás, ahonnan a rajongók (mit lehet rajongani egy pirosba öltözött brazilon, aki saját izzadságában tocsogva kínozza magát órákon át egy kormány csavargatásával?) megtudhatják, hogy:
"Felipe, one of our family"
"Negative CT scan outcome"
Továbbá:
"Countdown to next race: 26 days"
Remélem a magyar orvosok összerakják masszát poraiból, és az éppen aktuális egészségügyi miniszter (aki egyébként mindig láncdohányos) kitüntetheti a kórházat, és felragaszthatja az arany plakettet: "a kórházak F1-e". Szar lenne, ha innen, Bukarestből, azokon a szar, kátyús utakon kellene levezetnie a road to hellen...
BRÉKING, SOKKING! "Felipe speaking to his family! All the exams done by the Hungarian medical team was negative"
Az első fele jó hír -már amennyiben nem azt mondta a családjának, hogy "¿Quién carajos es usted?"-, viszont a másodikat nem értem. Ha az orvosi csapatnak az összes vizsgája negatív lett, hogy a pöcsbe' dolgozhatnak az ország legúgyabb kórházában?
Vagy ez már a szadesz-emeszpés reform in real action?
FreeBSD kernelparaméterek állítása DHCP-ből
2009.07.27. 05:23
Netbootos környezetben néha jól jöhet, ha a gépek kernelparamétereit finomabban is tudjuk szabályozni a /boot/loader.conf-nál, hiszen ez utóbbi -hacsak nem használunk valami okos NFS szervert, amelyik képes forrás IP alapján más-más tartalmat mutatni- minden azonos roottal rendelkező gépnél azonos.
Danny Branissnek köszönhetően az r187200-tól van lehetőség (STABLE ágon) arra, hogy DHCP-ből adjunk kernelparamétereket. Sajnos azonban ez a lehetőség alapértelmezetten ki van kapcsolva, így itt leírom hogy kell bekapcsolni, és használni.
Először is módosítani kell a fent hivatkozott bootp.c-t:
ki kell cserélnünk ezt:
#define DHCP_ENV DHCP_ENV_NO_VENDOR
erre:
#define DHCP_ENV DHCP_ENV_FREEBSD
Miután ezzel megvagyunk, újra kell fordítani a pxebootot (make buildworld-del ez is lefordul), majd értelemszerűen rá kell másolnunk a korábbi verzióra (oda, ahonnan TFTP-n letöltjük a bootfolyamat során).
Ezután már állítgathatjuk a kernelparamétereket, ISC DHCPd esetén például az alábbihoz hasonlóan:
subnet 192.168.178.0 netmask 255.255.255.0 {
option subnet-mask 255.255.255.0;
option broadcast-address 192.168.178.255;
use-host-decl-names on;
next-server 192.168.178.128;
filename "pxeboot";
group {
option class "wsfe";
option root-path "192.168.178.128:/imgs/wsfe/003";
option unknown-246 "vm.kmem_size=56G";
host wsfe0-10.web.dmz.intra {
hardware ethernet 00:23:7d:3c:af:5c;
fixed-address 192.168.178.10;
}
host wsfe0-16.web.dmz.intra {
option unknown-246 "vm.kmem_size=120G";
hardware ethernet 00:23:7d:3c:dc:14;
fixed-address 192.168.178.16;
}
Mint az a fent hivatkozott diffben megnézhető, 246-tól 249-ig lista, míg 250-től 254-ig "kulcs=érték" formájú paramétereket adhatunk át DHCP opciókban. Az, hogy több lehetőségünk is van, azt a célt szolgálja, hogy esetlegesen használt más opciókkal ne ütközzünk.
A lista formátuma ugyanaz, az elemek pontosvesszővel vannak elválasztva, pld. "vm.kmem_size=120G;kern.ipc.nmbclusters=200000".
A hierarchikus elrendezés pedig lehetőséget ad arra, hogy egy groupnál csak egy helyen kelljen állítani a paramétereket (bár ezeket akár a loader.conf-ban is állíthatnánk), és csak azoknál a gépeknél kelljen beírni őket, amelyek valamilyen okból eltérnek a többitől (például kevesebb memória van bennük).
Szerző: blackshepherd
Szólj hozzá!
Címkék: freebsd kernel dhcp parameter netboot dhcp env freebsd dhcp env no vendor bootp
Nomen est omen, telibe baszta, és pont Magyarországon :(
2009.07.25. 21:43
https://www.youtube.com/watch?v=3hfr29J4Xpo
Komment:
iam live in hungary... and i work in the hospital... i see Massa with my eyes.... he it isnt fine....
Akik nem tudnak angolul, fordítás a google által:
iam él Magyarország ... és dolgozom a kórházban ... Látom, Massa a szemem .... akkor ez isnt fine ....
Hát ez alapján még akár helyes is lehet a fordítás :-O

Szerencsére van még Magyarországon jó orvos, szorítok nekik, hogy a jó hírüket Massa sikeres gyógyulása útján is öregbíthessék!
A fogfúró a villám ellen
2009.07.21. 10:25
A modern HDD-k annyira pörögnek, hogy a fogdokim a tengelyükkel a lyukas örlőmet is könnyűszerrel porrá zúzhatná. De vajon ér-e valamit ez a nagy pörgés az atomvillanással szemben?
Szerintem nem, persze inkorrekt összehasonlítani a már említett low-end SSD-t egy 15 ezret forgó SAS HDD-vel, most mégis ez jön. Ráadásul ZFS-sel és UFS-sel is.










MiBps-ben is:










Az SSD-k nagy erőssége, hogy mozgó alkatrészek híján sokkal gyorsabb a válaszidejük (ahogy az az IOPS értékekből is látszik). Most megtudjuk, hogy mennyivel:


Ahogy látható, sokkal. A kontroller cache-e miatt a minimum válaszidők ugyanolyan alacsonyak a HDD-nél és az SSD-nél is, mind UFS, mind ZFS esetében, azonban az átlag és a 95%-ra számolt válaszidők már nagyobb eltérést mutatnak, UFS-nél az SSD ezredmásodperc alatti értékekkel működik, míg a ZFS esetében a késleltetés már nem annyira impresszív, de még így is töredéke a HDD-ének.
Ami feltűnően látványos az az, hogy az UFS nagy blokkméreteknél is szinten tudta tartani a válaszidőket (16 ms alatt), míg a ZFS ott már teljesen elszállt, cserébe viszont a nagyobb blokkméret miatt 128 kiB-ig nyújtott egyenletes teljesítményt az UFS 16 kiB-jával szemben.
Érdemes lenne megismételni a tesztet nagyobb UFS blokkmérettel is...
A ZFS, vagy az UFS SSD-barátabb?
2009.07.20. 11:01
Jó pár évig lehet blogbejegyzéseket írni azokból a számokból, amik pár nap alatt keletkeztek, de talán valaki egyszer hasznosnak találhatja őket...
Mai epizódunk arról szól, hogy a ZFS, vagy az UFS szereti-e jobban a korábban már bemutatkozott SSD-t, mindezt pedig FreeBSD (8) és OpenSolaris alatt. Ígérem hamarosan lesz Linux is. :)
Mivel az OpenSolarisban az UFS (azt gondolom) kihalófélben lévő állat, így arra nem pazaroltam a drága áramot.
A tesztek a szokásos sysbench grafikonok.






Kezdetnek itt van egy 100 ezer IOPS-es szekvenciális olvasás, amelyet az OpenSolaris mutatott be. Afelől nem sok kétségem van, hogy ezt az SSD önmagában képtelen lett volna produkálni, az a ZFS és a kontroller előreolvasásának köszönhető. A FreeBSD némileg lemaradt ZFS tekintetben, az UFS viszont szinte mindenhol szánalmasan alulteljesített, kivétel ezalól a véletlenszerű olvasás, ahol viszont péppé verte mind a FreeBSD-s, mind az OpenSolaris-os ZFS-t. Valami oka biztosan van, és ha több időm lett volna, pár rendkívül hasznos DTrace scripttel nyilván ki is deríthettem volna.
Valószínűleg köze lehet ahhoz, hogy a ZFS szeret egész blokkokat olvasni (amely elég kellemetlen hidegzuhany annak, aki ész nélkül vált egy hardveres RAID5-6-ról RAIDZ(2)-re, hiszen a HW-es megoldásnál megszokhatta (persze implementációfüggő), hogy a diszkek számának növelése az olvasási teljesítményt is növeli (random IOPS-ben), míg a RAIDZ-nél ez nem igaz, ott egy diszk teljesítményét kapjuk, ami váratlanul érheti azt, aki a legújabb X4500-asán meggondolatlanul csinált egy 48 diszkes RAIDZ poolt :), amelyet alátámasztani látszik a 128 kiB-nál bekövetkező kiegyenlítődés.
Az írási grafikonokból egy meglehetősen biztosan kijelenthető: FreeBSD-n UFS-t SSD-n használni tilos. Legalábbis ott, ahol írni is kell az eszközre. A véletlenszerű írási teljesítmény mélyen a ZFS-é alatt marad.
Persze nem könnyíti a helyzetet a gyatra SSD sem, amely -BBWC-s kontroller ide, vagy oda- így is csak egy HDD teljesítményét hozza. Természetesen aki utánaolvasott az SSD-k működésének, nem lepődik meg ezen, és vagy Intelt, vagy STEC-et vesz. Írásra. Olvasásra ez is megteszi, főleg ha UFS-t használ, vagy hozzáidomítja a ZFS-t a feladathoz.
Nézzük mi látszik MiBps fronton:






Válaszidők az albumban.
SSD FreeBSD 7-tel és FreeBSD 8-cal
2009.07.17. 12:00
Egy ismerős kapott kölcsönbe egy -amúgy elég low-end- SSD-t (itt: flash-alapú SATA-s HDD-nek látszó tárgy), így tudok néhány teszteredményt közölni róla.
A tesztgép az előző cikkben említett HP DL380, így az a nem túl szokványos helyzet állt elő, hogy az SSD nem egy natív SATA kontrolleren lógott, hanem egy köztes RAID vezérlőn, amely hozzáadta a maga BBWC-jét (akkumulátor védett írási cache), és persze rátette a saját kis processzora, és a "made in ind1a" firmware-e által okozott teljesítménycsökkenést.
Eredmények:






Ugyanez MiBps-ben:






Mint látható, a fiúk csináltak valamit a FreeBSD 8-ban, ami jelentősen megemeli a teljesítményét -legalábbis egy gagyi SSD-n- a 7-es verzióhoz képest.
Szerző: blackshepherd
Szólj hozzá!
Címkék: performance freebsd state disk ssd solid sysbench fileio iops ufs
FreeBSD soft updates vs. gjournal
2009.07.17. 11:07
A FreeBSD-s tábort sokáig cikizték azzal, hogy naplózó fájlrendszer híján egy-egy crash után (szerencsére ebből azért nem volt sok) percekig kell fsck-zni, míg helyreáll a rendszer. Aztán mikor megjelentek a több tíz GB-os diszkek, hosszú percekig. Aztán mikor ezeket a diszkeket RAID-be tettük, hosszú-hosszú percekig. Aztán mikor már száz GB-os diszkeket raktunk RAID-be, mert az UFS2 ezt megengedte, és ezeket a diszkeket jól megpakoltuk apró fájlokkal, akkor napokig is.
Aztán lett journaling fájlrendszer, pár próbálkozáson keresztül a ma talán leginkább használható a gjournal nevű (amelyből kettő is volt, Ivan Vorastól, és Pawel Jakub Dawidektől, itt ez utóbbiról lesz szó).
A gjournal -a nevéből adódik- a GEOM frameworkben ül, és ezáltal GEOM providereket naplóz blokkszinten, azaz elvileg az UFS mellett más fájlrendszerek is használhatják (de nem igazán fogják). A működéséhez az UFS-t kellett pár helyen módosítani, hogy a fájlrendszer-journal kapcsolat valamelyest teljesüljön, de a blokkszintűségből adódik, hogy más megoldásokkal szemben ez mindent naplóz, legyen az metaadat, vagy adat.
A napló amúgy egy fix méretű helyet jelent akárhol. Lehet azon az eszközön, amelyen maga a fájlrendszer, de lehet külön is.
A működése egyszerű, a legfontosabb állítható paraméter a journal váltási ideje, és a cache mérete. Ha ezek letelnek (és volt írás persze), a gjournal lezárja a journalt, újat kezd, és kiírja a lezárt tartalmát az adatdiszkre. Mivel a journal írása szekvenciális, a journalba írás nagyon gyors, függetlenül az írás jellegétől. Persze utána azt az adatot ki kell írni a diszkre is, az meg már nem lesz annyira Speedy Gonzales (Andale!).
Szóval a gjournal használata (külön journal diszk(ek)kel) gyorsíthat is akár, de persze a legfontosabb, hogy meggátolhatja az fsck-t (a hangsúly a feltételes módon van, ugyanis van, hogy ez nem teljesül, és fsck-zni kell, ez pedig érhet minket készületlenül).
A mérleg másik nyelve a jó öreg soft updates a legendás Kirk McKusicktól, amely úgy próbál játszani az írási műveletekkel, hogy a fájlrendszer integritása ne sérüljön, és fsck nélkül is működőképes maradjon (a soft updates-szel mountolt fájlrendszert tehát nem kell fsck-zni, egy lerohadás után anélkül is lehet használni, az fsck (amely tud háttérben is futni, jól lelassítva a gépünket) csak a levegőben lógó bejegyzéseket szabadítja fel, meg persze ha valami fájlrendszer korrupció volt, azt javítja -ha ilyenünk van, az fsck nélküli indítással egy vaskos panicot kockáztatunk-).
Na de nézzük a grafikonokat, FreeBSD 8 soft updates vs. gjournal egy darab 72 GB-os szingli 15k RPM-es SAS diszken:






A leglátványosabb grafikon a szekvenciális írás, ahol a gjournal négyszeresen ráver a soft updates-re nagyon pici blokkméreteknél. Ez nyilván annak köszönhető, hogy míg az UFS azon görcsöl, hogy mit is tegyen a fájlrendszer blokkmérete (16 kiB) alatti írással, addig a gjournal valóban szekvenciálisan kiírja a journalba, aztán amikor pedig a diszkre másolja, a RAID kontroller cache-ének segítségével már nagyobb adagokban tud folyni az adat a diszk felé.
A fájlrendszer blokkmérete gyönyörűen látszik szinte mindenhol, itt nagy ugrások vannak az optimális kiosztás miatt. Megmutatkozik a SAS diszk ereje is, amit a magas forgási sebesség, és a (viszonylag) gyors seekeléseknek köszönhet.
Nézzük ugyanezt MiBps-ban!






A szekvenciális olvasásnál látszik az adatdiszken tárolt napló legnagyobb hiányossága: a dupla írás. Soft updates-szel a diszk kb. 90 MiB-ot képes benyelni másodpercenként, amit a journalnál (némi overheaddel) duplán ki kell, hogy használjon a gép, azaz az írási teljesítmény feleződik.
Ami látványos, hogy ezt a maximumot már alacsony blokkméretnél (4 kiB) eléri, és utána tartja is, azaz ha lett volna még egy ugyanilyen diszkünk logdiszknek, kis blokkméreteknél igen jelentősen növekedett volna az áteresztőképesség.
Az életszerűbb random írás tesztekben viszont nagyobb nyert a soft updates, azaz akinek ilyen jellegű a workloadja, és megengedheti, használjon inkább olyat (vagy próbálja meg külön tenni a journalt), ezek szerint jobban jár.
ZFS sebesség, FreeBSD vs. OpenSolaris
2009.07.16. 17:20
Most, hogy a FreeBSD-ben lassan használható lesz játékra a ZFS, sokakban felmerülhet a kérdés, hogy mennyire sikerült a portolás teljesítmény szempontjából.
Bár a ZFS nem épp a sebességéről híres :), azért a legtöbb feladatra annyira nem is rossz. Mennyire sikerült tehát elrontania Pawelnek, Kipnek és úgy általában a FreeBSD-nek ezt a nagyon várt fájlrendszert?
Mint mindig, pontos válasz erre sem adható, mindenkinek saját magának kell kimérnie. Én a reprodukálhatóság kedvéért a sysbenchet használtam, annak is a fileio modulját.
A gép, amivel próbálkoztam egy meglehetősen elterjedt darab, HP DL380G5 (még egy korábbi szériából), benne HP SmartArray P400-as RAID vezérlő, rajta akksival védett 512 MiB cache, amelyet az alapértelmezett 3/4-es felosztásban használt írásra és olvasásra. A diszk, amit hajtottam, egy RAID0-ba rakott (a vezérlőben nem tudok passthrough eszközt definiálni, így valamilyen tömböt létre kellett hozni) egy darab 72 GB-os 15k fordulatszámú diszk volt.
Az oprendszereket FreeBSD oldalon egy friss -CURRENT(/amd64), míg az OpenSolaris részéről a 2009.06-os release képviselte.
Azért, hogy az OS cache-t kivédjem, a sysbenchnek azt mondtam, hogy minden írás után fsync()-eljen, illetve olyan mennyiségű adattal dolgoztattam meg, amelyik legalább egy nagyságrenddel nagyobb volt a gépben lévő memóriánál (azaz pld. 4 GiB RAM-ra 40 GiB adatmennyiség).
A sysbench fileio modulja képes több szálon is futni, azonban ezeket a teszteket csak egy szálon hajtottam végre. A teszt során a program méri többek között az átviteli sebességet (amely a blokkmérettel ide-oda átváltható MiBps-re és IOPS-re, azaz tranzakcionális sebességre) és a válaszidőt is, azaz azt, hogy egy művelet milyen gyorsan zajlott le. Ez utóbbi főleg a véletlenszerű műveleteknél fontos, hiszen hiába olvas gyorsan a diszk, ha lassan pozicionálja a fejet, és ha sávot kell váltani hosszú ms-okat szüttyög vele.
A sysbench a következő -élettől némileg elrugaszkodott- teszteket tudja: rndrd (véletlenszerű olvasás), rndrw (véletlenszerű olvasás-írás, ilyenkor a kettő közötti megoszlás alapból: R/W=1,5), rndwr (véletlenszerű írás), seqrd (folyamatos olvasás), seqrewr (folyamatos újraírás), seqwr (folyamatos írás).
Lássuk a medvét!






IOPS-ben mérve a két rendszer látszólag fej-fej mellett halad, általánosságban azonban kimondható, hogy egy hajszálnyival szinte mindig az OpenSolaris a nyerő.
A hatalmas IOPS értékek alacsony blokkmérettel leginkább a SmartArray kontroller cache-ének köszönhető, hiszen szekvenciális olvasáskor képes felismerni ezt a mintát, és előre dolgozni (a fájlrendszertől függetlenül), illetve íráskor is ahelyett, hogy rögtön a diszkre kellene tennie mindent, elteheti a cache-ében, visszaigazolhatja az írást, majd azokat összefogva, nagyobb mennyiségben delejezheti rá a lemezekre.
Szépen előjön a random teszteknél a diszkek -leginkább- seek idejéből adódó alacsony IOPS is, amely olvasásnál valahol a 170-es érték körül mocorog, míg írásnál 120 körülire esik.
Érdekesség a random írás tesztben a 128 kB-nál látható magas kiugrás. A zfs alapértelmezett blokkmérete ennyi, így tényleg megfontolandó ezt az értéket az alkalmazáshoz hangolni, mint látható, igen brutális növekedést jelenthet.
Szépek-szépek a fenti értékek, de az átlagembernek nem az IOPS, hanem az áteresztőképesség mond valamit. Nézzük a fenti számokat megabájt per másodpercben (MiBps)!






Mint látszik, lényegi különbség nincs a FreeBSD és az OpenSolaris között, kivéve a szekvenciális olvasást, ahol az IOPS ábrán látható hatalmas számok láthatatlanná tették a különbséget, amely most szépen előjött. Bár a grafikonon látványos eltérés adódik, az "csak" pár MiBps különbség, amelyet tovább növel (vizuálisan), hogy ez az egyetlen kiegyensúlyozott grafikon, ahol nincs nullához közeli érték, így az y origó is feljebb csúszott.
Végül nézzük meg, hogy mennyit kell várnia az alkalmazásnak a tesztben szereplő blokkokra:






Az y skálán logaritmikus léptékkel látható a válaszidő, azaz az az idő, amely a művelet indítása és lezárása között telt el, ezredmásodpercben.
Minden időértéknek három kategóriája van: a legkisebb, az összes érték átlaga, és a kérések 95%-át adó érték. A maximumokat nem tüntettem fel, mert néhol nagyon magasak voltak, és azt gondoltam, hogy a kérések 95%-át reprezentáló érték is jól kell, hogy jellemezze a teljesítményt.
Jelentősebb eltérések (meglepetés!) itt sincsenek, nem is lehetnek, hiszen annak a fenti grafikonokon is látszaniuk kellene.
A legérdekesebb a random read és write grafikon lehet, hiszen a legtöbb workload ilyen mintát mutat. Átlagértéke a gyártó által megadott átlagos seek time körül van, azaz nem hazudtak, mikor eladták nekünk ezt a diszket. :)
Szerző: blackshepherd
Szólj hozzá!
Címkék: performance hp freebsd opensolaris zfs sysbench iops smartarray dl380 throughput mbps
Python unladen swallow performance
2009.07.16. 11:11
Recently, there were some amount of buzz about Google's (?) project, named unladen swallow, which targets a considerable amount of speedup of (C)python interpreter.
I use a DNS server -written in python-, because it's flexible and easy to program, so I thought I should give unladen a peek.
| Test/result | Original python 2.6.2 | Unladen trunk (built on 2.6.1 python) | Unladen vs stock |
| IPv4 PTR | 1716 | 1756 | 2,3% |
| IPv4 A | 1864 | 1938 | 3,9% |
| IPv6 PTR | 1507 | 1572 | 4,3% |
| IPv6 AAAA | 2794 | 2895 | 3,6% |
One of the main parts of unladen swallow is the JIT, leaving out the bytecode interpreter. The above results are made with the default setting, which makes JIT to kick in only for "hot" code, which is executed a lot of times.
But there is a "-j always" option, which compiles every python code into native, so -in theory- they could run faster. In theory.
Running my program with "-j always", the machine began to work hard and instead of the normal few seconds startup time, I had to wait more than a minute.
After the compilation ended, I got this in top:
PID USERNAME THR PRI NICE SIZE RES STATE C TIME WCPU COMMAND
24653 root 3 116 0 767M 712M ucond 1 0:00 0.00% python
So python ate 712 MiB memory (otherwise it doesn't chew up more than 10-20 M), obviously because of the fact, that it had to compile every imported modules and load them into memory, or maybe it forgot to release the allocated memory at compile time...
Let's see how this performs against the default setting:
| Test/result | Default (-j whenhot) | -j always | whenhot vs. always |
| IPv4 PTR | 1756 | 1598 | -9% |
| IPv4 A | 1938 | 1769 | -8,8% |
| IPv6 PTR | 1572 | 1416 | -10% |
| IPv6 AAAA | 2895 | 2648 | -8,6% |
As it stands, it's better to leave -j at its default setting, and only compile the often used code -during run-.
As you can see, the performance increase in negligible, but I hope that it will change in the future. It would be good to have a python runtime environment, which preserves the language's flexibility and freedom, but offers more speed than Cpython.
A nagy öreg a fiatal csirke ellen - UFS vs. ZFS
2009.07.15. 19:38
Ha a HWSW melléklete lennénk, azt mondanám, hogy sok buzz volt nemrég a ZFS körül, de ennek ellenére még mindig nem tudunk róla mindent. A végén még egy feleséggyilkosság is kiderül. :)
Itt van tehát egy gyors UFS (soft updates) vs. ZFS összehasonlítás sysbench-csel, FreeBSD 8 alatt:






MiBps-ben számolva ugyanez:






A fentiek mellett a sysbench által mért válaszidők is elérhetők itt.
Szerző: blackshepherd
Szólj hozzá!
Címkék: performance hp sas hdd freebsd zfs iops ufs gjournal smartarray
ZFS és tömörítés
2009.07.11. 21:34
Ha valamiért úgy gondolnánk, hogy a ZFS nem elég lassú, könnyen segíthetünk a dolgon: kapcsoljuk be a tömörítést!
A fájlrendszer-tömörítésnek mindig is voltak támogatói és ellenzői is. Egy biztos: sosem volt annyi lóerő a gépeinkben, mint ma, és nevetséges az a teljesítmény, amit a mostani gépünk nyújt ahhoz képest, amit két év múlva fogunk használni.
Erő tehát van a digitális abakuszunkban, és évről-évre egyre több. Ez sajnos nem mondható el a diszkekről, amelyek bár kellemesen híznak (idén 2 TB-nál tartunk, két év múlva valószínűleg megint duplázunk), viszont a mérettel együtt az IOPS-nek nevezett paraméter, amely a diszkek tranzakcionális sebességét (amely a pozicionálási időkből -seek time- ered) mutatja, csak nem akar nőni.
Vannak 7200, 10000 és 15000-es fordulatszámon járó diszkjeink, és az átlagos seek time-ra már 2 ms-ot sem szégyellnek írni a gyártók, de ha a CPU-k sebességével mérjünk a diszkjeinket, már rég 1728000-as fordulatszámon kellene pörögniük, és 20-40 mikroszekundum alatt kellene válaszolniuk.
Szóval a teljesítménymérleg nyelve erősen eltolódott a diszkek felől a processzorok felé, így hát a tömörítés támogatói az mondják: miért ne használjuk az unatkozó CPU-(ka)t az adatok méretének csökkentésére, és így a lassú diszkek sebességének növelésére?
Logikus.
Próbáljuk ki. Van itt egy gép nyolc erős CPU maggal, meg egy rakás diszkkel. Másoljunk a diszkekre tömörítéssel, és még jobb tömörítéssel.
A ZFS jelenleg az LZJB-t (a ZFS (egyik) szerzőjének, Jeff Bonwicknek az LZ-like tömörítési algoritmusa, amely meglehetősen gyors) és a gzipet támogatja. Előbbi kevésbé tömörít, utóbbi jobban, de lassabban. Mennyivel? Ennyivel:
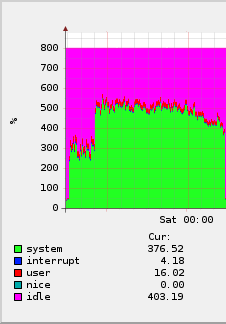
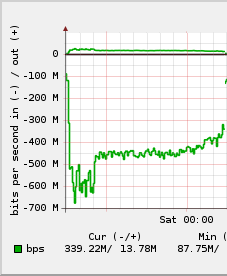
A CPU-terhelési grafikonon látható alacsonyabb kernelidő (zöld, 300% körül, azaz a nyolc magból kb. 3-at használt a kernel) az LZJB-re, míg a hirtelen ugrás utáni kb. 500% (azaz 5 mag) a gzip (default, azaz -6).
Mellette a hozzá tartozó hálózati forgalom, azaz LZJB-vel kb. 6-700 Mibps-t tudott benyelni a gép (több szálon történő rsynces másolással), míg gzippel csak kb. 450-et.
Ezt kb. be is hozza a tömörítésben, lzjb-vel a compressratio kb. 1,14x, míg gzippel 1,5 feletti.
Fontos megjegyezni, hogy a betömörítés és a kitömörítés nem (feltétlenül) szimmetrikus, azaz olvasásnál más lesz (vagy legalábbis lehet) a kép.
De ez messze nem tudományos igényű mérés, csak egy gyors ténymegállapítás. :)